키움증권 HTS 영웅문을 사용하는 사람은 아래 차트가 익숙할것이다.
[0600] 키움종합차트
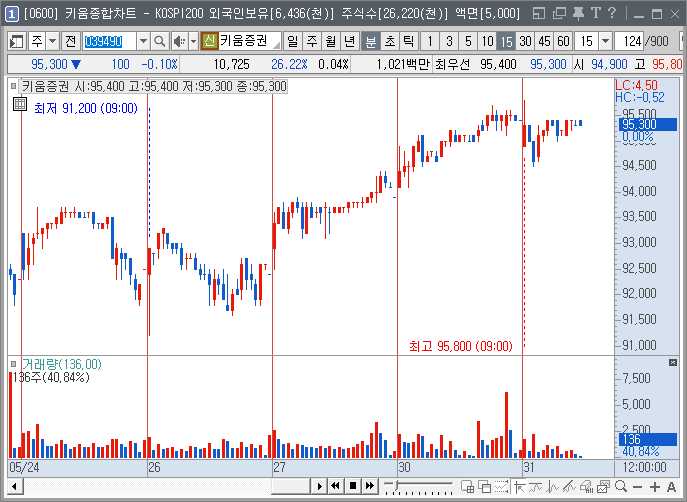
상단에 종목코드와 현재가 등 종목에대한 각종 데이타가 표시되어 있고 그 밑에는 분봉차트가 배열되어있는 모습이다.
이번 포스팅에서 다루게 될 항목은 다음과 같다.
- 키움종합차트를 캡쳐하여 이미지로 저장
- 저장한 이미지를 분석하여 현재가 및 종목코드 추출
- 종목코드를 가지고 네이버금융에서 종목명 추출
스크린캡쳐 (pyautogui)
pyautogui를 활용하여 현재화면을 파일로 저장한다.
import pyautogui
im = pyautogui.screenshot('img.png', region=(765, 202, 55, 18))여기서 region은 좌측 상단 (0, 0)을 기준으로 우측으로 765만큼 아래로 202만큼 이동한 지점을 기준으로 우측으로 55 아래로 18만큼 이동한 지점까지의 면적을 캡쳐하겠다는 의미이다. 사용자마다 HTS창 위치가 다르기 때문에 위의 수치도 다를 수 있다.
위의 코드를 실행하면 img.png 파일이 생성된다.

img.png 파일은 위와 같이 캡쳐된 시점의 주가를 포함한 이미지 파일임을 확인할 수 있다.
이미지 파일 분석, 현재가 추출 (pytesseract)
pytesseract는 이미지 파일을 분석하여 글자 또는 숫자 값을 추출해준다.
이를 사용하려면 모듈을 가져오는 동시에 간단한 프로그램 설치도 필요하다.
[pytesseract 다운로드]
https://github.com/UB-Mannheim/tesseract/wiki
GitHub - UB-Mannheim/tesseract: Tesseract Open Source OCR Engine (main repository)
Tesseract Open Source OCR Engine (main repository) - GitHub - UB-Mannheim/tesseract: Tesseract Open Source OCR Engine (main repository)
github.com
먼저 위 링크에 접속하여 파일을 다운로드 하고 설치해준다.
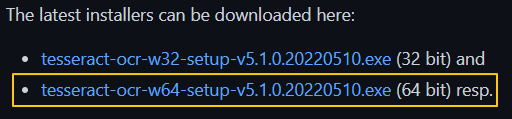
설치가 완료되면 아래 경로에 tesseract라는 프로그램이 설치된 것을 확인할 수 있다.

지금까지의 과정을 종합한 코드는 다음과 같다.
from PIL import Image
import pytesseract
import pyautogui
im = pyautogui.screenshot('img.png', region=(765, 202, 55, 18))
# 흑백 이미지로 변경(추출 정확도)
img = Image.open('img.png')
thresh = 200
fn = lambda x : 255 if x > thresh else 0
imgGray = img.convert('L').point(fn, mode='1')
imgGray.save('img.png')
# tesseract를 설치한 경로 설정
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
result = pytesseract.image_to_string('img.png')
print(str(int(result.replace(",","").replace(" ",""))) + "원")1. 스크린 캡쳐
2. 흑백 이미지로 변경
3. pytesseract로 숫자 추출
4. 추출된 숫자 수정 후 출력
이미지 파일의 주가와 추출된 주가의 값이 동일한 것을 확인할 수 있다.
이와 같이 자동으로 HTS화면에 표시된 종목의 현재가를 추출할 수 있다.
다음은 종목코드를 추출해보자.

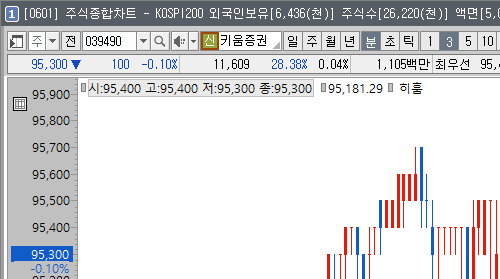
캡쳐 영역만 수정하면 동일한 방법으로 종목코드를 추출할 수 있다.
im = pyautogui.screenshot('img2.png', region=(835, 180, 50, 17))
img = Image.open('img2.png')
thresh = 200
fn = lambda x : 255 if x > thresh else 0
imgGray = img.convert('L').point(fn, mode='1')
imgGray.save('img2.png')
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
result = pytesseract.image_to_string('img2.png')
img2.png파일로 종목코드가 표시된 영역을 이미지 파일로 저장하고 현재가를 추출했던 동일한 방법으로 종목코드를 추출해보자. 추가적으로, 네이버 금융 사이트에 접근하여 해당 종목코드의 종목명을 추출해보자
from PIL import Image
import pytesseract
import pyautogui
from bs4 import BeautifulSoup
import requests
im = pyautogui.screenshot('img.png', region=(765, 202, 55, 18))
img = Image.open('img.png')
thresh = 200
fn = lambda x : 255 if x > thresh else 0
imgGray = img.convert('L').point(fn, mode='1')
imgGray.save('img.png')
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
result = pytesseract.image_to_string('img.png')
print(str(int(result.replace(",","").replace(" ",""))) + "원")
im = pyautogui.screenshot('img2.png', region=(835, 180, 50, 17))
img = Image.open('img2.png')
thresh = 200
fn = lambda x : 255 if x > thresh else 0
imgGray = img.convert('L').point(fn, mode='1')
imgGray.save('img2.png')
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
result = pytesseract.image_to_string('img2.png')
k = 'https://finance.naver.com/item/main.naver?code='
URL = k + result
headers = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36 OPR/67.0.3575.115'}
page = requests.get(URL, headers=headers)
soup = BeautifulSoup(page.content, 'html.parser', from_encoding="utf8")
stock = soup.find("div", class_="wrap_company").find("a").text
print(f'{stock}({result.strip()})')
아래는 HTS화면에서 캡쳐한 이미지를 통해 현재가, 종목코드를 추출하고 이를 통해 종목코드까지 불러온 모습이다.


'플그래밍 > 파이써언' 카테고리의 다른 글
| 정규표현식(regex) 연습 사이트 (0) | 2022.06.07 |
|---|---|
| [파이썬] 유저아이디 길이 확인하기, len() (0) | 2022.06.05 |
| [파이썬] 폴더 내 모든 폴더명 추출 (2) | 2022.04.16 |
| [파이썬 기초] 문자열 string (0) | 2022.03.18 |
| [파이썬 기초] 숫자 (0) | 2022.03.18 |